
Język programowania ABAP to podstawa systemu SAP. SAP NetWeaver Application Server ABAP (AS ABAP) jest bazowym serwerem aplikacji dla rozwiązań takich jak SAP Business Suite, SAP BW oraz innych oferowanych przez firmę SAP. Jednocześnie kluczowe nowinki technologiczne – jak chmura (Cloud), rozwiązania mobilne czy rozwiązania In-Memory – zapewniają klientom i partnerom firmy SAP zdolność do reagowania na nowe potrzeby biznesowe, a także oferują szansę wyróżnienia się wśród konkurencji poprzez wykorzystywanie technologii najwyższej klasy.
W artykule przedstawiamy zasadnicze elementy programowania aplikacji dla SAP HANA, które mogą poprawić szybkość działania oraz moc obliczeniową tworzonych rozwiązań. Dodatkowo zaprezentujemy kilka przykładów nowych możliwości, które SAP HANA oferuje programistom. Jednak zanim przejdziemy do szczegółów, należy zwrócić uwagę na dwie najważniejsze kwestie. Pierwszą z nich jest to, jak korzystać z języka programowania ABAP i zapytań SQL w nowym środowisku oferowanym przez SAP HANA. Druga kwestia to tworzenie rozwiązań w pejzażu systemów SAP.
ABAP i SQL w środowisku SAP HANA
SAP HANA jest zgodna z regułą ACID (Atomicity Consistency Isolation Durability), obowiązującą dla baz danych. ACID to zbiór właściwości, które gwarantują poprawne przetwarzanie transakcji w bazach danych. Rozwinięcie poszczególnych liter akronimu to:
Atomicity – atomowość transakcji oznacza, iż każda transakcja albo wykona się w całości, albo w ogóle, np. jeśli w ramach jednej transakcji odbywać ma się przelew bankowy (zmniejszenie wartości jednego konta i powiększenie innego o tę samą kwotę), to nie może zajść sytuacja, że z jednego konta ubędzie pieniędzy, a kwota na koncie docelowym będzie bez zmian: albo przelew zostanie wykonany w całości, albo w ogóle;
– atomowość transakcji oznacza, iż każda transakcja albo wykona się w całości, albo w ogóle, np. jeśli w ramach jednej transakcji odbywać ma się przelew bankowy (zmniejszenie wartości jednego konta i powiększenie innego o tę samą kwotę), to nie może zajść sytuacja, że z jednego konta ubędzie pieniędzy, a kwota na koncie docelowym będzie bez zmian: albo przelew zostanie wykonany w całości, albo w ogóle; Consistency – spójność transakcji oznacza, że po wykonaniu transakcji system będzie spójny, czyli nie zostaną naruszone żadne zasady integralności;
– spójność transakcji oznacza, że po wykonaniu transakcji system będzie spójny, czyli nie zostaną naruszone żadne zasady integralności; Isolation – izolacja transakcji oznacza, iż jeżeli dwie transakcje wykonują się współbieżnie, to zazwyczaj (zależnie od poziomu izolacji) nie widzą zmian przez siebie wprowadzanych. Poziom izolacji w bazach danych jest zazwyczaj konfigurowalny i określa, jakich anomalii możemy się spodziewać przy wykonywaniu transakcji.
Z technicznego punktu widzenia SAP HANA jest podobna do każdej innej bazy danych, z którą zdarzyło się pracować programiście. Wykorzystuje języki SQL i MDX, posiada biblioteki JDBC i ODBC, przechowuje dane w tabelach, w kolumnach i wierszach, wymaga administracji i tworzenia kopii zapasowych. Jednakże istnieje kilka kluczowych różnic i dostępnych jest kilka nowych możliwości, które powinny być brane pod uwagę podczas tworzenia aplikacji dla systemów z SAP HANA jako bazą danych. Przede wszystkim należy pożegnać się z kilkoma fundamentalnymi zasadami obowiązujących w poprzednich wersjach systemu, po to aby wykorzystać wszystkie nowe możliwości oferowane przez SAP HANA.
Pod względem technicznym SAP HANA jest zgodna ze standardowymi interfejsami każdej bazy danych. Dlatego też, aby zacząć jej używać, można by wykorzystać aktualnie działające aplikacje, zmienić ustawienia interfejsów ODBC lub JDBC, a następnie uruchomić je w taki sam sposób jak poprzednio, ale z SAP HANA jako nową warstwą bazy danych. Problem w tego typu scenariuszu jak jednak taki, że SAP HANA oferuje nowe możliwości, których brakuje innym bazom. Na niektóre z tych zalet składają się lepsze podstawowe możliwości techniczne bazy danych.
Ponadto SAP HANA znacznie wykracza poza tradycyjne bazy danych, oferując kompletną platformę aplikacyjną i rozwojową, jak również poszerza możliwości w takich dziedzinach, jak przeszukiwania, predictive analysis itd. Dlatego też budowa aplikacji z wykorzystaniem tych szczególnych zalet pozwoli programiście na stworzenie najbardziej innowacyjnych rozwiązań.
Bez ograniczeń
Jeszcze kilka lat temu, w tradycyjnej architekturze opartej na przestrzeniach dyskowych, napisanie złożonego algorytmu, który jednocześnie wybiera surowe dane z 200 dużych (100 milionów wierszy), unikatowych tabel i wykonuje „w locie” połączenia, było uważane za głupie i wręcz niemożliwe.
A co, jeśli to nie byłoby głupie lub niemożliwe? Co, jeśli ten algorytm ma ogromne znaczenie biznesowe dla użytkowników końcowych? Co, jeśli nie byłoby „kary” za napisanie tego algorytmu? Co, jeśli można by uzyskać wyniki tego typu obliczeń w ciągu kilku milisekund, a nie kilku godzin? Co jeśli programista miałby dostępny superkomputer do obliczania takiego algorytmu zawsze, kiedy tylko to potrzebne? Co jeśli oprócz wykonania tych operacji w bazie danych można by przenieść wszystkie inne warstwy aplikacji i prezentacji bezpośrednio do bazy danych, aby zapewnić prostą, nieskomplikowaną platformę, w której można by uruchomić całą aplikację?
Tego typu podejście to rodzaj zmiany filozoficznej wymaganej do przejścia od programowania w świecie ograniczeń do nowego świata SAP HANA. W świecie SAP HANA stare ograniczenia bazy danych i ograniczona moc obliczeniowa stają się w dużej mierze bez znaczenia. Granice takie jak to, gdzie kończy się baza danych, a zaczyna się serwer aplikacji, są także silnie kwestionowane.
Abstrakcja
W świecie SAP (a w świecie ABAP szczególnie), deweloperzy uczą się, aby całkowicie oddzielić swoje aplikacje od bazy danych i traktować ją jako „czarną skrzynkę”. Baza danych służy tylko do przechowywania danych, a silnik ABAP jest podstawowym miejscem odpowiedzialnym za całą logikę aplikacji i generowanie zapytań SQL. Programiści ABAP często dosłownie nie mają pojęcia, z jakiej bazy danych będzie korzystała ich aplikacja, dlatego też muszą stosować metody optymalne, ale bez wskazania konkretnej bazy danych.
Niestety, często ze względu na kompatybilność tworzonych rozwiązań muszą rezygnować z możliwości oferowanych przez poszczególne bazy danych. To skrajne oddzielenie logiki aplikacji i przechowywania danych jest jednym z fundamentów rozwoju aplikacji ABAP od ostatnich 20 lat, przede wszystkim dlatego, że była to najbardziej skuteczna strategia SAP w podejściu do osiągnięcia kompromisu pomiędzy szerokim wsparciem dla wielu baz danych i wydajnością poszczególnych aplikacji.
W przeciwieństwie do tego podejścia w świecie SAP HANA wiadomo dokładnie, z jaką bazą danych będzie współpracować tworzona aplikacja. Wiadomo również, że SAP HANA została zoptymalizowana do zaspokojenia potrzeb danej aplikacji. W konsekwencji nie tylko silnik ABAP może korzystać z szybkości pamięci procesora, może także skorzystać z wszystkich możliwości oferowanych przez SAP HANA dla obliczeń i funkcji biznesowych.
Z SAP HANA wiele zadań związanych z wydajnością jest faktycznie realizowanych i przeprowadzanych na poziomie bazy danych. A zatem SAP HANA pozwala programistom wniknąć głęboko w sam model danych. Ponadto jej funkcje pozwalają na wykonywanie intensywnych działań na poziomie danych, a nie w samej aplikacji, jak to było do tej pory w bazach danych opartych na dyskach.
W starym paradygmacie programowania programiści, projektując aplikację, pisząc jej logikę, przetwarzając dane, często pozostawiali bazę danych zupełnie nienaruszoną. Taka aplikacja pobierała potrzebne dane z bazy danych, przetwarzała je i przekształcała, następnie uruchamiała obliczenia i algorytm, i wreszcie przedstawiała użytkownikowi wyniki końcowe.
W SAP HANA proces jest niejako odwrócony. Aplikacja odpowiedzialna jest tylko za logikę biznesową. Wywoływana funkcja jest odpowiedzialna w całości za pobrania odpowiedzi z bazy danych. Przekształcenia danych, algorytm i obliczenia są wykonywane wewnątrz bazy danych, a jedynie ich wynik jest przekazywany z powrotem do aplikacji.
Przeniesienie wszystkich operacji intensywnego przetwarzania danych na poziom bazy danych i wywołanie tych działań jako funkcji z poziomu aplikacji sprawia, że cała architektura staje się znacznie bardziej elegancka i efektywna. W rzeczywistości firmy, które zdecydowały się na zastosowanie SAP HANA, odnotowują poprawę wydajności aplikacji o setki tysięcy razy.
To przejście od przetwarzania danych na poziomie aplikacji do manipulacji danymi na poziomie bazy danych jest niezbędne do korzystania z wszystkich możliwości zawartych w SAP HANA. Oczywiście przy migracji na SAP HANA można nadal korzystać ze starych aplikacji i uzyskiwać nieco krótszy czas odpowiedzi, ponieważ kolejna zaleta bazy danych SAP HANA to fakt, że znajduje się ona w pamięci. W momencie przeniesienia operacji intensywnie wykorzystujących dane bezpośrednio na poziom bazy danych SAP HANA można uprościć nie tylko architekturę i usprawnić działanie aplikacji, można również zauważyć zdecydowaną poprawę ich wydajności.
Programowanie ABAP dla SAP HANA
Ponieważ ABAP jest podstawowym językiem programowania aplikacji w rodzinie SAP Business Suite, odgrywa ważną rolę w przeniesieniu obecnej bazy klienta do SAP HANA. W związku z tym wiele osób interesuje się, w jaki sposób mogą wykorzystać SAP HANA w SAP Business Suite i jak mogą wykorzystać ABAP do wykorzystania możliwości oferowanych przez SAP HANA. Istnieje kilka różnych konfiguracji, w których ABAP i SAP HANA mogą pracować razem, aby stworzyć i wykorzystać innowacyjne możliwości w SAP Business Suite.
Poniżej omówione zostanie kilka scenariuszy wykorzystujących siłę SAP HANA w nowych i istniejących aplikacjach SAP Business Suite. Scenariusze te wahają się od bardzo prostych aplikacji, niewymagających przerywania pracy systemu w celu przyspieszenia problematycznych transakcji lub raportów, aż do uruchamiania całego systemu SAP Business Suite bezpośrednio z SAP HANA jako główną bazą danych.
SAP HANA jako dodatkowa baza danych
W tym scenariuszu przyjmijmy, że SAP HANA została zainstalowana jako pomocnicza baza danych, a nie jako zamiennik dla istniejącej. Następnie za pomocą replikacji można przenieść kopię danych z oryginalnie funkcjonującej bazy danych do systemu SAP HANA. Aplikacje ABAP mogą zostać przyspieszone, ponieważ będą one odczytywać dane z kopii SAP HANA, zamiast z lokalnej bazy danych.
Najprostszym rozwiązaniem dla wykonywania operacji SQL z poziomu języka ABAP w podłączonej zewnętrznej bazie danych jest użycie zapytań Open SQL, które są doskonale znane programistom ABAP. Poprzez wypełnienie dodatkowych parametrów w składni CONNECTION (dbcon) można wymusić, aby instrukcja Open SQL została wykonana w podłączonej, alternatywnej bazie danych.
Na przykład weźmy prostą instrukcję SELECT i wykonajmy ją na bazie HANA:
Zaletą tego rozwiązania jest jego prostota. Poprzez jeden drobny dodatek do istniejących komend SQL można przekierować zapytania do SAP HANA. Minusem jest to, że tabela lub wgląd, skąd pobierane są dane, musi istnieć w Słowniku Danych ABAP (ABAP Data Dictionary).
W przypadku tego scenariusza nie jest to jednak duży problem, ponieważ wszystkie dane znajdujące się w lokalnej bazie danych ABAP są replikowane do SAP HANA. W tej sytuacji lokalne kopie tabel danych zawsze będą istnieć w słowniku ABAP. Należy jednak pamiętać, że w ten sposób nie można uzyskać dostępu do specyficznych dla SAP HANA dodatków, takich jak widoki analityczne (Analytic Views) i procedury bazy danych. Nie można także uzyskać dostępu do żadnych tabel, które istnieją tylko i wyłącznie po stronie SAP HANA.
Połączenie ABAP do zewnętrznej bazy danych poprzez Native SQL
W składni języka ABAP jest również możliwość wykorzystania Native SQL. W tym scenariuszu kod zawiera elementy składni SQL specyficzne dla konkretnej bazy danych. Proces ten pozwala na dostęp do tabel i innych elementów bazy, które istnieją tylko w podstawowej bazie danych. Ponadto Native SQL zawiera składnię, która pozwala wywołać procedury bazy danych. Powyższy przykład możemy przepisać przy użyciu Native SQL w następujący sposób:
Wadą stosowania języka Native SQL poprzez wykorzystanie komendy EXEC SQL jest to, że w takim podejściu brakuje sprawdzenia poprawności tworzonych zapytań SQL. Ewentualne błędy nie zostaną wychwycone do czasu wykonania zapytania, co może prowadzić do błędów wykonania ABAP (tzw. „short dumps”) w przypadku braku implementacji obsługi tego typu wyjątków w kodzie. To ograniczenie sprawia, że w przypadku wykorzystania Native SQL testowanie rozwiązania jest absolutnie niezbędne do zapewnienia poprawności działania.
Połączenie ABAP do zewnętrznej bazy danych poprzez Native SQL – ADBC
Trzeci scenariusz zapewnia korzyści z połączenia Native SQL poprzez EXEC SQL z wyeliminowaniem niektórych ograniczeń. W tym przypadku mamy do czynienia z pojęciem ADBC – ABAP Database Connectivity, na które w istocie składa się cykl standardowych klas ABAP (CL_SQL*). Dzięki metodom klas ADBC możliwe jest przesyłanie specyficznych dla bazy danych zapytań SQL i przetwarzanie wyników, a także ustanawianie i administrowanie połączeniem z bazą danych, a to wszystko zostaje obudowane w kod upraszający skomplikowaną składnię EXEC SQL. Nasze przykładowe zapytanie można przepisać w następujący sposób:
W tym przypadku usuwamy jednokrokowy dostęp do bazy danych dla każdego wiersza i zastępujemy odczytem całego pakietu danych do naszej tabeli wewnętrznej. Z punktu widzenia SAP HANA najważniejszy jest fakt, że w przypadku wykorzystania właściwości ADBC możliwy jest dostęp do „niesłownikowych” (non-Data Dictionary) elementów bazy danych, w tym procedur przechowywanych po stronie SAP HANA. Biorąc pod uwagę te zalety ADBC nad EXEC SQL, SAP rekomenduje każdorazowe wykorzystywanie klas ADBC.
Powyższy przykład przedstawia bardzo proste zapytania SQL, jednakże prawdziwe zalety stosowania SAP HANA jako zewnętrznej bazy danych można odczuć podczas wykonywania bardziej zaawansowanych zapytań (SELECT SUM … GROUP BY), dostępu do specyficznych atrybutów SAP HANA bądź procedur bazy danych.
SAP HANA jako podstawowa baza danych
Oczywiście SAP HANA może być wykorzystywana jako podstawowa baza danych w każdym systemie opartym na języku programowania ABAP. W ramach SAP Business Suite opartego na SAP HANA aplikacje oparte na ABAP (jak ERP) mogą być uruchamiane z SAP HANA jako podstawowym systemem zarządzania bazą danych. W tym przypadku język ABAP również musiał zostać rozszerzony, aby dostarczyć nowe narzędzia i techniki oraz umożliwić programistom bezpośredni dostęp do szczegółowych funkcji SAP HANA.
Do tej pory przedstawiliśmy, w jaki sposób z poziomu ABAP można uzyskać dostęp do zewnętrznej bazy danych za pomocą Open SQL oraz Native SQL. Wiemy również, że Open SQL jest ograniczony tylko do obiektów zdefiniowanych w słowniku ABAP (ABAP Data Dictionary). W odpowiedzi na te ograniczenia w ABAP 7.4 pojawiło się nowe podejście pod nazwą Data Dictionary Proxy Views – słownikowe wglądy Proxy. Wglądy Proxy pozwalają programistom na tworzenie wpisów w słowniku ABAP, specyficznych dla wglądów SAP HANA – Analytic, Attribute and Calculation views. Programiści mogą korzystać z wglądów Proxy (Proxy Views), wpływając na jakość i łatwość wykorzystania Open SQL wobec wglądów specyficznych dla SAP HANA. Takie podejście jest szczególnie przydatne, gdy połączone jest z pewnymi rodzajami typów ABAP – jak Select-Options i Parameters.
Kolejna nowość w ABAP 7.4 dotycząca SAP HANA to procedury Proxy (Proxy Procedures). Procedury Proxy generują zarówno interfejs ABAP, jak i typy danych specyficzne dla procedur przechowywanych w SAP HANA. W tym celu wprowadzona została nowa składnia ABAP (CALL PROCEDURE), dzięki której wywołanie procedury z SAP HANA wygląda bardzo podobnie do wywołania modułu funkcyjnego ABAP.
Zarówno wglądy Proxy, jak i procedury Proxy sprawiają, że wykorzystanie Native SQL staje się zbędne w przypadku dostępu do funkcji specyficznych dla danej bazy danych. Dzięki obu tym dodatkom programiści muszą wykonać zdecydowanie mniej pracy, aby zaprojektować kod wykorzystujący możliwości SAP HANA. Pozwalają one także na poprawę efektywności transferu danych pomiędzy serwerem aplikacji ABAP a SAP HANA.
Przetwarzanie danych bliżej bazy danych
Niezależnie od tego, czy SAP HANA używana jest jako podstawowa, czy dodatkowa baza danych, programiści muszą przyjąć różne strategie projektowania kodu, jeśli chcą wykorzystać wszystkie zalety SAP HANA. Programiści ABAP zazwyczaj unikają skomplikowanych zapytań SQL na rzecz przetwarzania danych na poziomie serwera aplikacji ABAP.
Takie podejście służyło programistom ABAP przez wiele lat. W celu pobrania danych z tabel zależnych od klucza obcego w języku ABAP możemy napisać poniższy kod z wykorzystaniem instrukcji inner join:
Jednak wielu programistów wybrałoby inne podejście, w którym połączenie danych zostanie wykonanie na poziomie serwera aplikacji poprzez wykorzystanie tabel wewnętrznych:
Takie podejście może być korzystne, jeśli wykorzystywane w zapytaniu tabele są buforowane. Powyższe przykłady służą pokazaniu dostępnych wzorców projektowych, a nie technicznych aspektów tych zapytań.
W jaki sposób zmieni się podejście programisty, jeśli dodamy do tego jeszcze SAP HANA? W przypadku HANA programista powinien dążyć do przeniesienia jak największej liczby operacji na poziom bazy danych. Można postawić sobie pytanie, dlaczego?
Aby na nie odpowiedzieć, należy pamiętać, że SAP HANA to baza danych typu In-Memory. Każdy programista doceni zalety konsolidacji wszystkich danych w szybkiej pamięci, w przeciwieństwie do przechowywania danych w stosunkowo wolnej przestrzeni dyskowej. Gdyby jednak była to jedyna zaleta oferowana przez SAP HANA, trudno byłoby zauważyć ogromną różnicę w porównaniu do przetwarzania w ABAP. Ostatecznie ABAP również oferuje pełne buforowanie tabel w pamięci.
Pozostałe kluczowe punkty architektury SAP HANA to, obok przetwarzania w pamięci, przechowywanie danych w kolumnach i przetwarzanie równoległe. W pętli ABAP dla tabeli wewnętrznej każdy rekord tabeli musi być przetwarzany sekwencyjnie, po jednym rekordzie na raz, a obecna wersja składni ABAP nie została zaprojektowana do przetwarzania równoległego. Zamiast tego ABAP wykorzystuje wiele procesów serwera, uruchamiając różne sesje użytkowników w oddzielnych procesach (work process).
W przeciwieństwie do tych ograniczeń SAP HANA może równolegle przetwarzać bloki danych w pojedynczym zapytaniu. Fakt, że dane przechowywane są w pamięci, dodatkowo wspiera przetwarzanie równoległe przez łatwiejszy i szybszy dostęp procesora do danych. Równoległe przetwarzanie wcale nie będzie pomocne w momencie, gdy procesor spędza większość czasu bezczynnie, czekając na dostęp do danych.
Kolejny istotny aspekt techniczny to kolumnowa architektura SAP HANA. Gdy dane przechowywane są w formie tabeli w kolumnach, wszystkie dane dla jednej kolumny przechowywane są w pamięci. W przeciwieństwie do przechowywania danych w wierszach – tak jak przetwarzane są tabele wewnętrzne ABAP – do pamięci ładowany jest tylko jeden wiersz na raz.
Zatem, dla wyżej wspomnianego warunku połączenia (Join), wartości dla kolumny CARRID w każdej tabeli mogą zostać odczytane szybciej ze względu na sposób rozmieszczenia danych. Przeszukiwanie niepotrzebnych danych w pamięci nie jest aż tak obciążające jak wykonanie tej samej operacji na dysku (ze względu na konieczność oczekiwania na obrót talerza). Przechowywanie danych w kolumnach zmniejsza koszty wykonania takich czynności jak przeszukiwania jednej lub więcej kolumn, a także optymalizacja procedur kompresji.
Z tych powodów programiści (a zwłaszcza programiści ABAP) muszą przemyśleć stosowane wzorce projektowe. Aby wykorzystać maksimum korzyści, jakie oferuje SAP HANA, muszą oni również przenieść na poziom bazy danych większość operacji wykonywany do tej pory po stronie ABAP. Wiąże się to z większym wykorzystaniem zapytań SQL i częstszymi interakcjami z bazą danych. W ten sposób baza danych staje się kolejnym narzędziem programistycznym, którego możliwości powinny być w pełni wykorzystywane.
SAP HANA Extended Application Services (XS)
Razem z SAP HANA SP5, SAP wprowadza nowe możliwość pod nazwą SAP HANA Extended Application Services (zwane również XS lub XS Engine). Koncepcja tego rozwiązania opiera się na osadzeniu w pełni funkcjonalnego serwera aplikacji, serwera WWW i środowiska programistycznego w ramach SAP HANA. Nie jest to tylko element oprogramowania zainstalowany na tym samym urządzeniu co SAP HANA, a w pełni zintegrowana nowa funkcjonalność usług aplikacyjnych na poziomie bazy danych SAP HANA. Dzięki tej innowacyjnej architekturze zwiększa się wydajność aplikacji i możliwy jest dostęp do wielu specyficznych cech SAP HANA.
Przed wprowadzeniem SAP HANA SP5, aby zbudować prostą stronę internetową lub usługę korzystającą z SAP HANA, konieczne było wykorzystanie innego serwera aplikacji w środowisku systemów (system landscape), np. poprzez wykorzystanie SAP NetWeaver ABAP lub SAP NetWeaver Java połączonego z SAP HANA, aby przekazać do niego zapytania SQL. Ten mechanizm jest nadal możliwy, zwłaszcza gdy istniejące aplikacje rozszerzane są o nowe funkcjonalności SAP HANA – taka integracja jest łatwa do wykonania i niesie za sobą minimalne ryzyko zakłóceń.
Gdy jednak nowe specyficzne dla SAP HANA aplikacje budowane są od postaw, warto rozważyć opcję wykorzystania SAP HANA XS. Z tą nową architekturą możliwe jest tworzenie i wdrażanie aplikacji całkowicie niezależnych w ramach SAP HANA. To podejście pozwala na obniżenie kosztów tworzenia oprogramowania, zapewniając jednocześnie wysoką wydajność rozwiązań, ponieważ sama aplikacja i kontrola logiki przebiegu programu znajdują się tak blisko bazy danych.
SAP HANA Studio – nowe środowisko programistyczne
Aby wesprzeć programistów w tworzeniu aplikacji i usług bezpośrednio w SAP HANA XS, firma SAP rozszerzyła SAP HANA Studio o wszelkie niezbędne narzędzia. SAP HANA Studio to narzędzie oparte na Eclipse (platformie do tworzenia aplikacji, zintegrowanym środowisku programistycznym). Dzięki tym dodatkom możliwe jest zarządzanie całym cyklem życia wszystkich elementów (zasobów) programistycznych (wglądy SAP HANA, procedury SQLScript, role, HTML i zawartość JavaScript itp.).
SAP HANA Studio zostało rozszerzone o nowe elementy zwane SAP HANA Development. Dodatki takie jak kreator projektów, autouzupełnianie kodu i podświetlanie składni, integrowany debugger itp. zwiększają produktywność programistów.
Wszystkie prace programistyczne w tym środowisku wykorzystują możliwości standardowo dostępne na platformie Eclipse – takie jak praca zespołowa. Pliki projektowe przechowywane są w repozytorium SAP HANA wraz z wszelkimi innymi zasobami. Członkowie zespołu mogą korzystać z przeglądarki repozytorium SAP HANA, aby sprawdzać istniejące projekty i importować je bezpośrednio do lokalnych obszarów roboczych. Następnie programiści mogą pracować na lokalnych wersjach kodu, często w tym samym czasie. W momencie ponownego zapisu kodu do repozytorium SAP HANA narzędzie wykryje wszelkie konflikty, a programiści mogą na bieżąco scalać fragmenty kodu bezpośrednio w repozytorium.
Repozytorium SAP HANA obsługuje również aktywne/nieaktywne obiekty obszaru roboczego. Dzięki tej funkcji programiści mogą bezpiecznie zapisywać swoje prace na serwerze, bez natychmiastowego nadpisywania aktualnej wersji. Nowa wersja kodu nie zostanie stworzona, dopóki programista nie aktywuje obiektu repozytorium.
SQLScript
Jak już wspomniano, podstawą optymalizacji dla aplikacji przenoszonych do systemu SAP HANA jest przeniesienie jak największej liczby operacji na poziom bazy danych. Realizacja tego celu rozpoczyna się z wykorzystaniem standardowego języka zapytań SQL. Jeśli jednak chcemy tworzyć logikę biznesową na poziomie bazy danych, konieczna jest również semantyka, która przekracza możliwości SQL. W tym celu SAP dostarcza właśnie takie rozszerzenie SQL o nazwie SQLScript.
SQLScript jest podstawowym językiem do tworzenia procedur składowanych i funkcji w SAP HANA. Dzięki rozszerzeniom dostarczanym przez SQLScript programiści mają możliwość przeniesienia większej liczby operacji na poziom bazy danych.
Typowe zapytania SQL znakomicie nadają się do przetwarzania równoległego dzięki swojemu deklaratywnemu charakterowi. Podstawowa słabość SQL staje się oczywista, gdy wyniki jednego zapytania należy przekazać jako dane wejściowe do kolejnego zapytania. W tym przypadku programiści mają dwie możliwości: skopiować wyniki zapytania do serwera aplikacji albo napisać skomplikowane, zagnieżdżone zapytania SQL z wykorzystaniem podzapytań lub wielu warunków połączeń.
SQLScript rozwiązuje ten problem poprzez dostarczenie możliwości przekazywania danych z jednego zapytania SQL do kolejnego. Dzięki tej funkcji programiści mogą pisać kod analogiczny jak w przypadku wykorzystania serwera aplikacji, a także deklarować zmienne i wykorzystywać pośrednie wyniki zapytań. Dodatkowo SQLScript może być często łączony z podzapytaniami i połączeniami różnych tabel (joins). Dzięki tym funkcjom programiści otrzymują składnię, która jest mniej skomplikowana i bardziej czytelna, jednocześnie zapewniając logikę przystosowaną do bazy danych. Równocześnie SQLScript unika wysyłania ogromnych kopii danych do serwera aplikacji, a wykorzystuje skomplikowane przetwarzanie równoległe w bazie danych.
W porównaniu ze standardowym SQL, SQLScript ma kilka zalet. W rezultacie przetwarzania procedury mogą zwracać wiele wyników, podczas gdy zapytanie SQL może zwrócić tylko jeden zestaw wyników. Kolejna zaleta to podział złożonych zapytań SQL na mniejsze kawałki. Dzięki temu możliwe jest programowanie modułowe, ponowne wykorzystywanie funkcji i lepsza zrozumiałość kodu.
Dodatkowo standardowa składnia SQL pozwala tylko na definicję wglądów SQL, jednak te wglądy nie mają ani parametrów, ani stałego interfejsu. Kolejną przewagą SQLScript jest obsługa zmiennych lokalnych bez jawnie określonych typów. W standardowym SQL widoczne globalne wglądy muszą być zdefiniowane, nawet gdy wykorzystywane są tylko do przechowywania pośrednich wyników zapytań. Idąc dalej, SQLScript posiada logikę sterowania taką jak if/else, niedostępną w standardzie SQL. Wreszcie SQLScript może zwiększać ogólną wydajność poprzez wykorzystanie przetwarzania równoległego w ramach większości wykonań kodu napisanego przy użyciu SQLScript.
Powyżej zostały przedstawione najistotniejsze aspekty pracy programisty z środowiskiem SAP HANA. Tworzenie aplikacji w ramach SAP HANA to bardzo złożony temat, jednak skala możliwości rozwoju oprogramowania w tej technologii jest ogromna. Maksymalna użyteczność aplikacji przy maksymalnym wykorzystaniu infrastruktury bazy danych otwiera zupełnie nowe perspektywy rozwoju rozwiązań dla biznesu.
Kilka dni temu pojawiła się wiadomość, że w ramach ostatniej aktualizacji w Raspberry OS, Fundacja Raspberry Pi zainstalowała repozytorium Microsoft na wszystkich komputerach jednopłytkowych, które jej zaufały, bez wiedzy ich właścicieli.

Manewr nie przeszedł niezauważony w społeczności Linuksa, który wkracza do walki z brakiem przejrzystości i telemetrii oraz użytkownikami płyty Raspberry Pi dyskutują, w tym wezwanie do repozytorium Microsoft na Raspberry Pi OS oraz dodanie klucza Microsoft GPG dla niezawodnej instalacji pakietu.
Repozytorium Microsoft jest dodawane przy użyciu pakietu raspberrypi-sys-mods, który obejmuje skrypty i ustawienia specyficzne dla systemu operacyjnego.
Konfiguracja /etc/apt/sources.list.d jest modyfikowana przez skrypt post-inst i służy do konfigurowania środowiska programistycznego VSCode. Główne twierdzenia są związane z tym, że repozytorium Microsoft i klucz zostały dodane bez ostrzeżenia użytkowników.
Ideą dodania repozytorium apt firmy Microsoft jest ułatwienie korzystania ze środowiska programistycznego Visual Studio Code.
Oficjalnie to dlatego, że obsługują IDE Microsoftu (!), Ale dostaniesz to, nawet jeśli zainstalujesz go z wyraźnego obrazu i użyjesz swojego Pi bez głowy bez GUI. Oznacza to, że za każdym razem, gdy wykonujesz „apt update” na swoim Pi, wysyłasz ping do serwera Microsoft. Instalują także klucz Microsoft GPG używany do podpisywania pakietów z tego repozytorium. Może to potencjalnie prowadzić do scenariusza, w którym aktualizacja pobiera zależność z repozytorium firmy Microsoft, a system automatycznie ufałby temu pakietowi.
Instalacja repozytorium odbywa się po cichu, bez zgody użytkownika, a Raspberry Foundation nie przygotowała użytkowników na taką zmianę poprzez dedykowany wpis na blogu.
Zirytowani użytkownicy komentują, że eTakie zachowanie jest niebezpieczne z dwóch powodów:
Po pierwsze, za każdym razem, gdy informacje o repozytoriach są aktualizowane podczas instalowania lub aktualizowania pakietów, menedżer pakietów sonduje wszystkie podłączone repozytoria, to znaczy eSerwer Microsoft gromadzi informacje o adresach IP wszystkich użytkowników System operacyjny Raspberry Pi, za pomocą którego można utworzyć profil użytkownika.
Podobny profil można wykorzystać na przykład do ukierunkowanej reklamy podczas logowania się do usług Microsoft z tego samego adresu IP.
Po drugie, repozytorium Microsoft jest połączone jako w pełni godne zaufania, mimo że nie jest pod kontrolą twórców systemu operacyjnego Raspberry Pi, a użytkownicy nie byli proszeni o potwierdzenie dodania klucza Microsoft GPG. Jeśli infrastruktura firmy Microsoft zostanie naruszona przez takie repozytorium, fałszywe aktualizacje mogą być rozpowszechniane w celu zastąpienia standardowych pakietów lub zależności.
Mówi nawet dalej
To jest sposób, w jaki cały czas robisz rzeczy „dla podobnych problemów” bez informowania właścicieli linii komputerów jednopłytkowych. »Użytkownicy przypomnieli sobie napięcia między Linuksem a Microsoftem związane z telemetrią.
Na koniec należy zauważyć, że dystrybucja Raspbian obsługiwana przez społeczność nie jest dotknięta problemem, zmiana została dodana tylko do Raspberry Pi OS, wariantu Raspbian obsługiwanego przez Raspberry Pi Foundations.
Innym podejściem jest zablokowanie Visual Studio Code, jeśli chcesz nadal korzystać z Raspberry Pi OS. Visual Studio Code jest wyposażony w opcje telemetrii, więc wielu użytkowników uważa, że Visual Studio Codium jest bardziej odpowiedni.
Aby wyeliminować dostęp do serwerów Microsoft w systemie operacyjnym Raspberry Pi, po prostu skomentuj zawartość pliku /etc/apt/sources.list.d/vscode.list i usuń klucz / etc / apt / trust key. Gpg.d / microsoft .gpg.
Ponadto do / etc / hosts można dodać adres „127.0.0.1 w celu blokowania żądań.
Wreszcie, jeśli chcesz dowiedzieć się więcej na ten temat, możesz się skonsultować poniższy link.
O tym, co to jest Arduino i dlaczego mi się podoba, pisałem w poprzednim poście. Teraz przyszła kolej, żeby wspomnieć o sednie całej zabawy – środowisku programistycznym. Wszak to między innymi dzięki łatwości programowania Arduino jest tak interesujące dla „przeciętnego człowieka”.
Programy dla Arduino tworzy się w języku opartym na platformie Wiring i przypomina bardzo uproszczone narzecze C/C++. Jakkolwiek mało przyjaźnie by to mogło zabrzmieć, oznacza ni mniej, ni więcej, że każda osoba mająca jakieś, choćby minimalne doświadczenie w języku C (a tak naprawdę jakimkolwiek języku programowania), po przeczytaniu krótkiego poradnika, szybko zacznie pisać proste programy. Ich konstrukcja jest wszak bardzo prosta, a masa przykładów, które można znaleźć w sieci, pozwoli szybko rozwiać ewentualne wątpliwości, lub nawet pisać oprogramowanie metodą „kopiuj/wklej”. Już samo środowisko programistyczne zawiera mnóstwo przykładów o różnym stopniu złożoności, napisanych tak, żeby łatwo je było zrozumieć. Bardzo dobrym punktem startu do nauki programowania będzie tutoral ze strony projektu Arduino.
Często najtrudnejszy w nauce programowania w nowym języku jest pierwszy krok – konfiguracja środowiska, uruchomienie pierwszego programu. Zapewne wiedzieli o tym autorzy projektu i uprościli start jak tylko się da. Na początek trzeba zainstalować srodowisko programistyczne. W Ubuntu, którego używam na codzień, robi się to w najprostszy możliwy sposób – wybierając Arduino IDE z centrum oprogramowania i klikając install lub przez wydanie komendy „sudo apt-get install arduino” w terminalu. Program zostanie ściągnięty z repozytorium i automatycznie zainstalowany. W innych dystrybucjach Linuksa instalacja wygląda podobnie, jeżeli Arduino IDE jest w standardowym repozytorium. Jeżeli nie, to w ostateczności można pobrać program ze strony projektu i go ręcznie zainstalować. Użytkownicy Windows muszą samodzielnie ściągnąć program i przejść tradycyjną dla tego systemu procedurę instalacji.
Po uruchomieniu IDE można wybrać z menu wczytanie przykładowego kodu programu (np. File/Examples/Basics/Blink), który po kliknięciu przycisku Upload zostanie automatycznie wysłany do podłączonego Arduino. Jeżeli mamy nietypową płytkę (czyli inną niż obecnie Arduino Uno), to należy ją wybrać wcześniej z menu Tools/Board (starszy kontroler może wymagać także wciśnięcia przycisku Reset dla wgrania programu). Jeżeli zachodzi potrzeba wybania portu, to odpowiednie ustawienie znajdziemy w menu Tools/Port. Dla Linuksa Arduino Uno przedstawi się prawdopodobnie jako /dev/ttyACM0 (/dev/ttyACMx jeżeli mamy więcej urządzeń opartych o Abstract Control Model, np. jakiś modem 3G).
Gdy program zostanie wysłany do podłączonej płytki, od razu zacznie działanie. Jeżeli był to program mrugający diodą podłączoną do pinu numer 13 (Blink z dołączonych przykładów), to możemy od razu zaobserwować jego działanie, ponieważ trzynaste wyjście jest połączone z diodą, która znajduje się na każdej płytce drukowanej Arduino Uno. Aby się przekonać czy rzeczywiście program jest wysłany poprawnie (dla niedowiarków, bo jakby coś było nie tak, to otrzymalibyśmy komunikat błędu), to można zmienić wartości funkcji delay (np. 1000 na 500) i zaobserwować, że dioda mruga w innym tempie.
W ten sposób najtrudniejszy krok mamy za sobą. Teraz pozostało tylko pisanie coraz bardziej złożonych programów i konstruowanie układów elektronicznych podłączonych do odpowienich pinów naszej płytki (bo ile można mrugać diodą). Tutaj bardzo pomoże lektura wspomnianego wcześniej samouczka. Warto go przeczytać i zapoznać się z różnymi ciekawymi funkcjami i prezentowanymi prostymi technikami programistycznymi, użytymi do zobrazowania rozwiązywania prostych problemów, które napotyka się podczas tworzenia realnych układów. Poza przykładowymi programami, dołączone są też schematy podłączenia różnych czujników, przycisków, diód, itp. wraz z wyjaśnieniem dlaczego coś działa w dany sposób, dlaczego czasem trzeba dołączyć rezystor, a innym razem kondensator czy jak poprawnie wykrywać wciśnięcie przycisku, który jak się okazuje nie jest urządzeniem doskonałym.
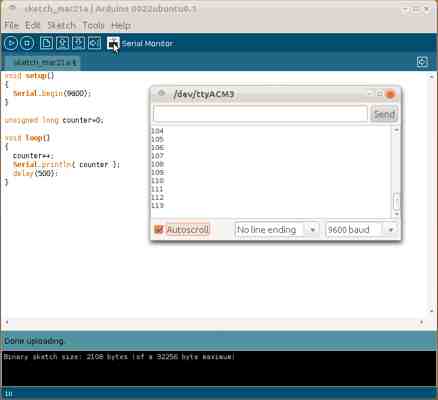
Arduino IDE daje oczywiście więcej możliwości, niż tylko wysyłanie programów do urządzenia. Warto wspomnieć o monitorze portu szeregowego. Gdy uruchomimy program, wtedy klikając przycisk Serial Monitor otwieramy prostą konsolę szeregową, która pozwala się komunikować z programem (o ile program zakłada taką komunikację rzecz jasna). Powyższy zrzut ekranu przedstawia prosty program liczący co pół sekundy od zera wzwyż i wysyłający aktualny stan licznika przez port szeregowy. Ten prosty program działał na moim Arduino podłączonym do routera z OpenWRT przez prawie miesiąc, dla sprawdzenia czy platforma jest stabilna. Nie było problemów, nic się nie zawiesiło.
Przy pomocy IDE możemy też wgrać do mikrokontrolera bootloader Arduino (gdy np. chcemy skonstruować własny, budżetowy klon) lub też zaprogramować jeden z układów ATtiny lub ATmega do działania niezależnego od Arduino. Zapewne kiedyś jeszcze o tym napiszę.
Gdy chcemy opublikować kod programu Arduino, to pomocna może się okazać funkcja kopiowania do schowka kodu wraz z formatowaniem HTML. Dzięki temu wklejony na stronę kod wygląda jak poniżej (z kolorowaniem składni analogicznym do sposobu prezentacji w Arduino IDE).
/* Blink Turns on an LED on for one second, then off for one second, repeatedly. This example code is in the public domain. */ void setup () { // initialize the digital pin as an output. // Pin 13 has an LED connected on most Arduino boards: pinMode (13, OUTPUT ); } void loop () { digitalWrite (13, HIGH ); // set the LED on delay (100); // wait for a second digitalWrite (13, LOW ); // set the LED off delay (1000); // wait for a second }
Arduino IDE to bardzo proste w obsłudze, ale też wygodne narzędzie o możliwościach, na które nie wskazuje pierwszy rzut oka na tę aplikację. Mimo, że nie jest to najbardziej rozbudowane IDE na rynku, ale ma wszystko czego potrzeba do programowania Arduino i rozpoczęcia zabawy z mikrokontrolerami. Właśnie prostota, połączona z łatwością programowania sprawia, że przygodę z Arduino może zacząć praktycznie każdy, niezależnie od posiadanego doświadczenia programistycznego. Choć oczywiście, jak można się spodziewać, umiejętność programowiania w innych językach (szczególnie C) może pomóc.
Jeżeli będzie zapotrzebowanie, postaram się napisać w przyszłości kilka słów o programowaniu Arduino. Niezastąpione w nauce będą jednak samodzielne eksperymenty, chociażby z modyfikacją gotowych przykładów.

Leave a Comment